

When starting in a new position at GRID, it is highly likely that not many hours (or perhaps even minutes) pass on your first day, before the first time somebody utters the term ‘game title agnostic’. It might even be that the term isn’t new to you, because it was discussed already a few times during the interview…
Such is the vital importance we attach to this concept as a cornerstone of GRID’s vision.
In this article, I’m going to outline why it is so important, and how we’ve gone about turning the concept of ‘game title agnostic’ technology into a reality on the GRID Data Platform.
Let’s start with why.
When GRID was founded, a little over 5 years ago, the state of play was painfully clear. Esports data was incredibly fragmented, largely unavailable, and most of what was available was unofficial, unreliable, and often lacking in detail.
It was clear to us that there must be a better way. We envisioned solving this by building technology that game developers could rely on to collect the data so sorely sought after, and a platform to make this data available — in all its granular glory — to their data-hungry communities.
GRID’s mission statement is to unlock the potential of in-game data for everyone. This not only includes every consumer with a data use case, but also any game developer looking to harness the value of their in-game data assets.
Thinking about the sheer number of developers and games that they have and will create, something else became clear to us. We needed to develop a scalable approach that would enable the GRID Data Platform to allow an extremely efficient adoption of new titles, and any future changes to those titles, within any genre.
The esports and gaming industry is incredibly fast-paced and hugely diverse. For those of us working within it, this is part of what we love about it. However, it also certainly brings some challenges.
New games constantly debut across varied genres. Some skyrocket to fame, amassing millions of players in a flash. Whether crafted by major studios or a solo developer on a tight budget, successful games will likely go on to receive regular updates and alterations, often shaped by player feedback.
In such a landscape, picture the daunting task of completing a large integration project every time you wish to tap into data for a new game. Now, think about revisiting that process with each game update or content expansion. While it might be feasible for top-tier games, this approach doesn’t scale efficiently, making the decision to onboard a new title increasingly challenging.
And this is exactly why we hold the concept of being game title agnostic so central to our vision — we don’t ever want it to be challenging for us to support more game titles on the GRID Data Platform, or for the downstream data application developers to consume the data available for them. Neither would we want a delay in a change to the game being reflected in the data. Finally, when building new platform features, we’d rather they benefit every title, rather than just one.
What does it mean to be game title agnostic?
Being game title agnostic is being able to build and operate products without needing to be concerned about the title that you are building or operating them for.
At GRID, this means ensuring that every one of the myriad of components that we build that make up the data platform as a whole, can work for any title. At a high level, the platform is made up of several broad layers, and each of these layers needs to be able to function and provide the same value, no matter the title it is providing it for.
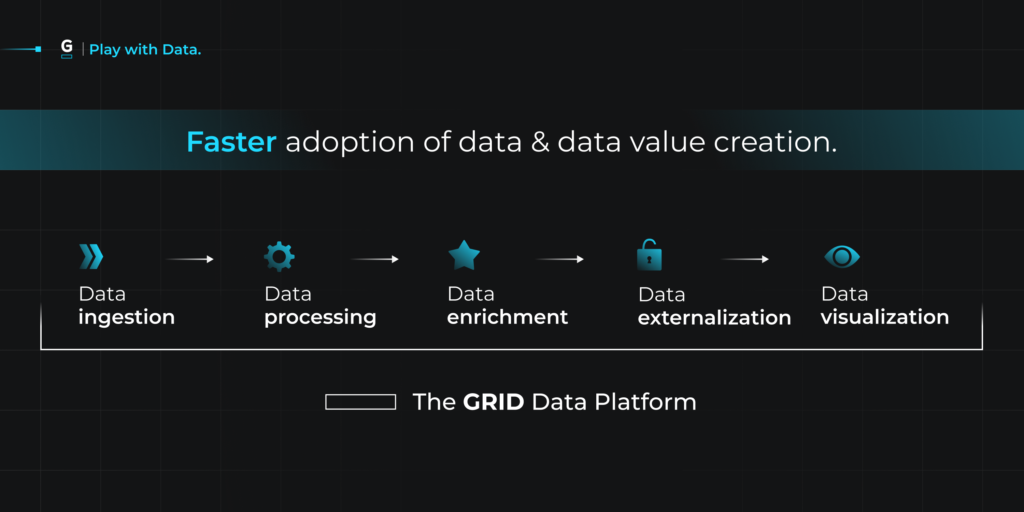
The gold standard we hold ourselves to at GRID is that data for a new title can be transmitted to GRID, and everything, end to end, becomes immediately available without any development work whatsoever. On top of that, we ensure that the way we provide data to downstream consumers allows them to do just the same, but with much less effort.
We’re not just passing through.
The gold standard we hold ourselves to at GRID is that data for a new title can be transmitted to GRID, and everything, end to end, becomes immediately available without any development work whatsoever. On top of that, we ensure that the way we provide data to downstream consumers allows them to do just the same, but with much less effort.
In recent years, the term game title agnostic has started to be used more and more in the industry, and not just by us. Often the approach being discussed, however, is quite different. More often than not, I’ve come across what could rather be described as ‘the passthrough approach’.
If you take data from a source, wrap it in standardized metadata (i.e. include some sequencing mechanism, perhaps attach an ID, add on timestamp) and publish it again, then it is probably quite obvious that data for a new title could be consumed and forwarded on again without needing to require much development work.
This approach, however, doesn’t come with a lot of value creation for either the data producers (game developers), or the data consumers (those building data driven applications).
The data producers still need to create a full API and build a data format that makes sense for the end consumers (as this will just be wrapped in metadata), and the data consumers still need to understand a new format, every time they wish to integrate a new title.
This is not the approach GRID has taken, because we don’t think this adequately solves the problem. While it might scratch the surface in some ways, it certainly isn’t going to help with GRID’s mission of unlocking the full potential of in-game data for everyone. To do that, you need an approach that maximizes accessibility and adoption.
How do we achieve this at GRID?
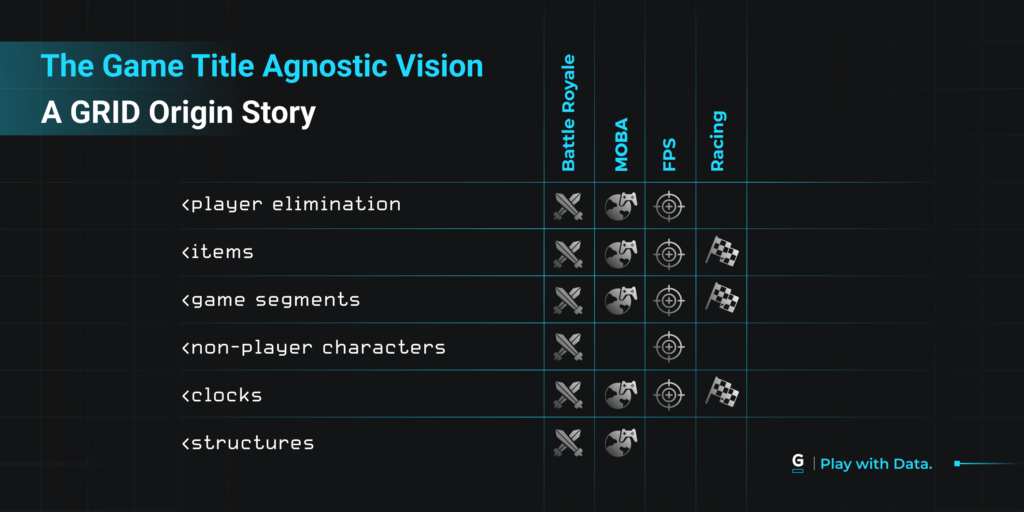
At the heart of our approach to achieving this, is ensuring that there is a standardized way to model different games. While on the surface this might seem an impossible task (how can data be standardized for MOBA, Battle Royale, and Racing games?), we’ve found the solution lies in first breaking down the games into smaller elements.
Although games may appear vastly different when viewed in their entirety, a closer examination of their mechanics often reveals significant similarities in how they function as playable experiences. The GRID Data Platform is engineered to enable us to build out support for these generic mechanisms that can then be used to model a title in data.
The following are some example mechanisms that we support, to illustrate what I mean.
- Segments — a game can be split into multiple parts, a segment can be won and all data that is collected can be attributed to the segment it occurs within.
- Objectives — players or teams can achieve things, and a count of the amount of times they have done so is maintained.
- Clocks — an important mechanism in many games, be it the main game clock, a cooldown timer, or a respawn countdown. A clock can count up, down, and be started, stopped or set.
- Items — players can interact with them, purchasing, picking up, dropping and using them.
- Abilities — players can carry out certain special actions. Abilities can be used, have a name and might not always be available.
- Structures — buildings that exist in the environment, they can have health, be controlled or destroyed.
- NPCs — non-player characters, can cause damage to players, be damaged or killed by players and controlled by a team.
These are only a small selection of the mechanisms available, just to give an idea. The full list is a lot longer at this point, and also includes some more basic mechanisms such as matches, games, players and teams.
These different generic mechanisms then become the building blocks with which to model a game and create a data feed for it. Each one enables a certain set of behaviors that are exposed in the following forms.
- Commands — functionality that allows game developers to transmit to GRID details of what is happening during a game, and informs the GRID platform of how to alter the state. Each mechanism supported has a set of commands with which to interact with it.
- State — a complete overview of the current circumstance of an ongoing game.
- Events — a set of supported events for each mechanism, that details what action has specifically happened, and how that action has altered the state over time (see here for further reading on state and events at GRID).
These work to achieve the game title agnostic vision set out above because:
- A data feed for any game can be modeled from the same mechanisms. All the mechanisms need not be used, of course, if they are not required.
- Logic produced to support these mechanisms can be reused across titles. If systems are designed well, this can result in supporting new titles without any work. GRID has developed various downstream applications that all leverage the approach to this effect.
Bringing it all together.
In the dynamic world of esports and gaming, we at GRID recognize the imperative need for efficient and scalable data solutions, in order to empower a thriving and sustainable data ecosystem. The game title agnostic approach is pivotal in achieving this.
By embracing this methodology, we empower a broader spectrum of game developers to offer data across numerous titles. Simultaneously, it unlocks opportunities for data consumers to access and utilize information from a wide array of games.
This post serves as a preliminary overview of our game title agnostic philosophy, its underpinning motivations and our practical approach to its implementation. Given the depth and intricacies involved, however, there’s certainly more to unpack on the topic in the future. Stay tuned.
In the meantime, to take a more detailed look at the actual results of the above approach yourself, you can apply for GRID Open Access. You can also find me on X, where I’m often talking about official esports and gaming data, the GRID Data Platform and its benefits.
